

GEO优化万字长文,如何让AI相信你
 2089
2089
系统学习运营课程,加入《91运营网VIP会员》,开启365天运营成长计划>>
|
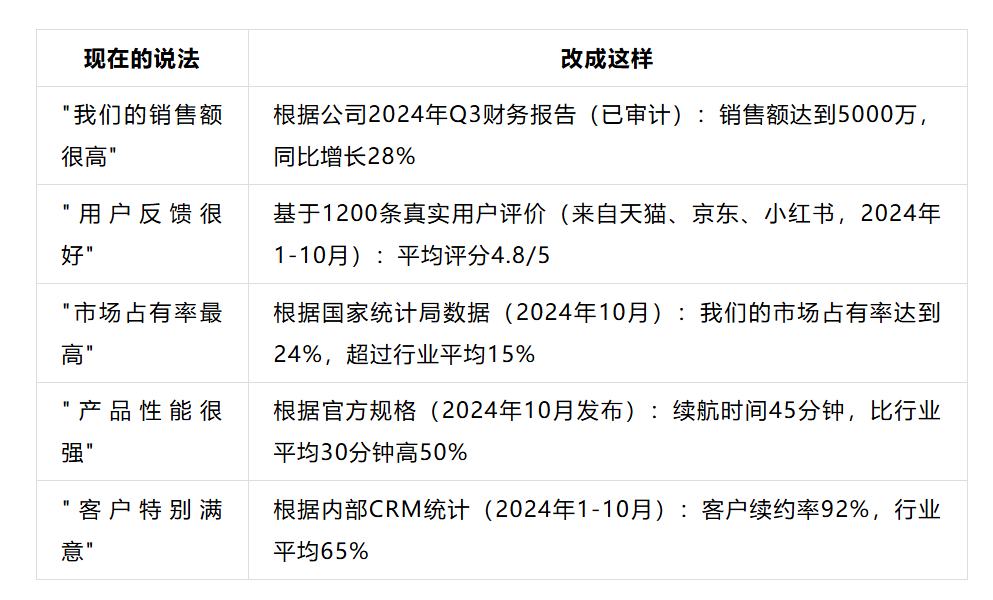
GEO优化的本质是什么? 简单说,就是让你的内容成为AI的首选知识库,进而通过GEO实现用户的最终转化。 这个过程分为四个递进的步骤: 第一步:让AI能理解你 第二步:让AI能相信你 第三步:让AI在答案中优先展现你 第四步:让用户转化成行动 前面一章我们已经解决了被理解的问题, 今天这章,我们通过这五个点, 1、AI凭什么信你?看懂≠引用的残酷真相 2、AI给你打了多少分?揭秘信任度计算公式 3、从5%到80%引用率:你在哪一层决定生死 4、5步提升AI对你的信任 5、拿来就用:AI信任度提升工具包 系统地解决”被相信”的问题,因为在AI时代,被看见不等于被相信,被相信才是被引用的前提。
这就像你看懂了一个销售员的话,不代表你会相信他、买他的产品。 理解和相信,是两码事。 传统搜索引擎Google、百度的工作很简单:用户搜”手机推荐”,系统匹配相关的网页,按排名展示。 搜索引擎不需要判断这些信息是真是假,它的工作是匹配,不是判断,只要你写的关键词恰好出现在这个网页上,就有机会被展示, 但AI完全不同。当你问ChatGPT或者是deepseek:”请推荐一个靠谱的无人机品牌”, ChatGPT不是在”查询”答案,而是在”生成”答案。 它需要从训练数据中调用信息,组织成一个连贯的回应。这个过程中,ChatGPT会问自己一个关键问题: “我应该优先使用哪些信息源?” 因为AI核心还是权威决策,他的第一性原理,就是内容是一些正确的内容, 这个问题的答案,只有ai相信你,才能决定了你的内容会不会被引用, AI怎么判断信息源的优先级? 为什么不同的信息源有不同的优先级?因为AI在处理信息时,必须做出权衡。海量的信息中,哪些更值得信任?哪些更可能准确?哪些风险更低? 你写得再清楚,AI也得问自己三个关键问题。 第一个问题:这个信息从哪来? AI会问:”这个信息来自谁?” 不同的来源,可信度权重完全不同。 官方说的(官网、新闻发布会、财务报告),我们如果按照打信任分的话,是100分; 媒体说的(人民日报、专业行业媒体),这种打分信任分的话,是95分; 知名用户反馈(有身份的、有认证的),这种打信任分的话,是80分; 用户说的(真实评价、购买记录),这种打信任分的话,是70分; 营销文案的话(就是自己说自己好),这种打信任分的话,是40分; 不知道谁说的(听说的),这种打信任分,就是5分; AI能看出这些区别, 同样一个观点,如果来自”官方财报”和”听说的”,权重能相差20倍。 信息源就像证人,有的证人很可信,有的证人可疑。 AI会根据证人的身份来判断相信的价值。 第二个问题:这个信息能验证吗? AI会问:”这个说法能被验证吗?”也就是说你这个说法,能不能被验证, 可验证的信息有这些, 具体的数字(3.8次/天,而不是”很高”)、 明确的时间(2024年10月,而不是”最近”)、 来源出处(引用自哪份报告)、 可追溯的证据(能找到原始数据)。 不可验证的包括:模糊的形容(优秀、强大、特别好”)、模糊的时间(现在、最近、目前)、无来源声明(从何而来)、无法比较(最好、行业最高)。 可验证的得分高,不可验证的自动打折,因为可验证意味着可追溯、可核实、风险低。 第二个问题:能验证吗? AI在问:你的说法可追溯、可核实? 你说的数字是多少?我能查证吗? 你说的时间是什么时候?我能追溯吗? 你说的来自哪里?我能找到原文吗? 你说的和别人比怎样?我能对标吗? 这一连串问题的核心其实就一个:”我能不能验证你说的?” 如果能,AI就信。如果不能,AI就打折。 可验证 , 就是有一个很具体的东西 具体数字:2次/天,而不是很高 明确时间:2024年10月,而不是最近 有一个明确的来源:引用自哪份报告, 比较清晰的对标:和竞品比是什么水平 不可验证 ,都是模糊的东西 模糊的一些形容:优秀、强大、特别好 模糊的时间:现在、最近、目前 无来源:谁说的不知道 无对标:最好、行业最高 为什么AI重视可验证性? 因为可验证 = 可追溯 ,这就意味的风险低, 所以:同一个观点,用具体数据说和用模糊形容说,AI给的信任分能差一倍。 第三层:内容一致性和历史信誉 AI会问:这个说法,具有历史一致性吗? AI不会只看你现在说什么,更会看你过去是怎么说的,它会检查你的历史记录, 是否被用户质疑过不准确?你现在说的和之前说过的是否一致?数据有没有自相矛盾的地方? 如果一个品牌过去的记录清白,发过的信息都被验证是准确的, 用户反馈一致,那么它发布新信息时,AI会自动给它一个初始信任值。 因为概率上,靠谱的来源下次也更靠谱。 你会发现,ai的判定,跟人的判定也差不多,这么看ai其实挺像人的。 这包括几个子问题:
如果一个品牌历史清白、数据一致、用户认可度高,那么它发布的新信息,AI会给个”初始信任值”。 反之,如果一个账号经常改口、数据矛盾、用户投诉多,那么即使说得再好听,AI也会打问号。 所以,建立信誉比现在就完美更重要, 一个新品牌要做的,就是每次都说实话、每个数据都准确、每次承诺都兑现,慢慢积累信誉。一旦信誉建立起来,后面的事情就会变得容易得多。 看懂不等于相信 这三个问题的答案,决定了你的内容会不会被优先引用。只要其中一个问题的答案不够有力,AI就会犹豫。 这就是为什么有些内容被看到95%,但被引用的只有10%。 ——因为AI看懂了,但不信。 看懂是第一关,信任才是第二关。 你需要同时通过两关,才能真正被AI使用。 因此, 决定你被AI引用多少次的,不是你写得有多漂亮,而是你有没有建立完整的信任体系。 而信任体系的核心,就是这四个关键指标:
这四个维度合起来,决定了有多少人会看到你,更重要的是,有多少人会相信并引用你。 这就是为什么,在AI时代,构建信任比构建内容本身更重要。
这不是AI的主观偏好,而是一套经过训练形成的判断机制。 AI信任机制的底层逻辑,来自惩罚驱动的学习。 在RLHF(人类反馈强化学习)阶段,AI每生成一次错误信息,系统就会被惩罚。 比如AI引用了一个不准确的数据,就会被打低分; 推荐了一个有争议的品牌,就会被标记错误; 使用了无法验证的说法,就会被降低权重。 经过成千上万次这样的训练, 其实就是跟我们人类进行考试一样,通过考试,对知识点的强化会越来越好, AI学会了一件事:凡是没有依据、没有来源、模糊不清的表达,都要自动降权。 AI不是因为喜欢权威来源,而是因为引用权威来源被惩罚的概率更低。 那么具体到实际操作中,AI是怎么给内容打分的? 说白了,AI给每个内容打分的方式,就像银行给你打信用分一样。它不会简单地说”信”或”不信”,而是会算出一个具体的分数。 这个分数怎么算?看这个公式: 信任度 = 权威性(35%) + 准确性(25%) + 可验证性(25%) + 时效性(15%) 你看,权威性占的比重最大,达到35%。为什么?因为权威来源出错的概率最低,AI最怕出错。准确性和可验证性各占25%,历史记录好不好、能不能查证,这两项加起来占一半。时效性占15%,相对来说没那么重要。 AI就是用这个公式,给每一块内容打分。 我们来看个对比。 内容A:”我们的产品很好用” 这句话会被打多少分? 权威性:5分(谁说的?不知道) 准确性:20分(好用到什么程度?说不清) 可验证性:10分(全是”很好用”这种虚词) 时效性:10分(什么时候说的?不清楚) 算下来,综合得分只有11.25分。 内容B:”根据官方Q3财报:我们的用户满意度4.8/5(基于1200条真实评价)” 这句话能打多少分? 权威性:100分(官方财报,最可靠) 准确性:95分(数据可以验证) 可验证性:95分(具体数字、明确来源) 时效性:90分(Q3最新数据) 算下来,综合得分能到96.75分。 同样是说”产品好”,一个11分,一个97分。这就是为什么引用率能差10倍。 再说一个更关键的:AI的信任分不是一成不变的,它会动。 就像你的芝麻信用分,按时还款就涨,逾期了就降。AI也一样: 分数会涨的情况: 你发的内容被很多人引用,而且反馈都说”对” 你的数据被好几个权威来源验证过 你的信息前后一致,从不自相矛盾 分数会降的情况: 你发的内容经常被人质疑 你的数据被打脸过 你今天说A,明天说B,前后矛盾 所以AI的信任系统,更像是一个”流动的信用评分”: 新品牌:刚开始分数低,得慢慢攒信誉 老品牌:如果历史清白,一开始就有高分 黑历史品牌:即使现在改了,信用也得慢慢恢复 这就是为什么,长期坚持说真话、发准确数据,比一次性包装得完美更重要。 一句话说清楚:AI信任你,不是靠感觉,是靠算分。 你的文案再漂亮,AI不会因此给你加分。它只看三件事:你的内容历史上准不准、你的逻辑前后自不自洽、你的来源够不够权威。 AI的目标很简单:谁让我出错的风险最低,我就用谁。 所以,要让AI相信你,靠的不是华丽的话术,而是一套实打实的、能验证的、有背书的信任体系。
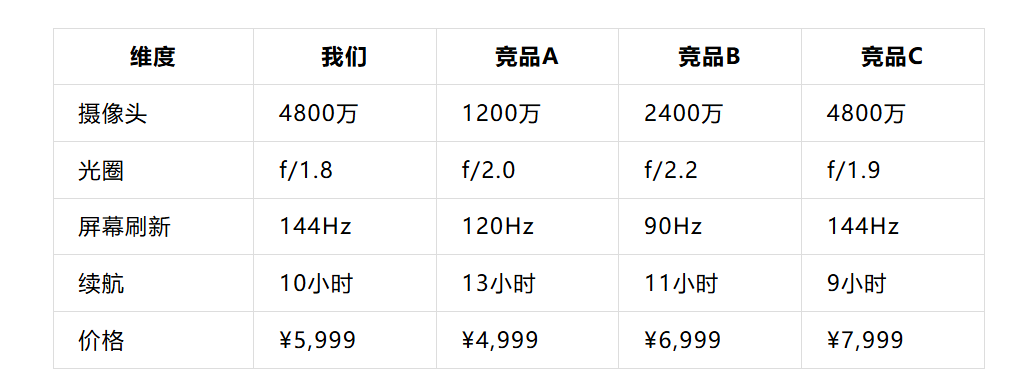
但可信度不是简单的”信”或”不信”,而是有明确的层级划分, 就像信用卡额度,有人是5000,有人是50万,差别巨大, AI根据你的综合得分,会把你的内容分到5个不同的层级, 每个层级对应不同的引用率,从5%到80%+,差距能达到16倍, 可信度是有梯度的, 从AI的角度,可信度分成5个层级,你的内容现在处在哪一层,决定了会有多少人看到你, 第1层:无可信度(引用率大概5%) 这类内容AI会直接忽视。 特征: 全是模糊形容词(特别好、非常强) 没有任何数据支撑 看不出来源(谁说的) 和事实矛盾(说自己销售额百亿,但团队只有5个人) 充满营销腔调(震惊、秒杀、绝了) 例子: “这个产品绝了!功能特别强大!用户特别满意!强烈推荐!” AI的判断:这是超级垃圾内容,九直接过滤掉。 第2层:低可信度(引用率大概15%左右) 有一些信息,但缺少证明。 特征: 有一些具体数字,但来源不清 有用户评价,但不知道真的假的 信息不够系统(说的很零散) 例子: “这个手机拍照很好,有用户说拍照效果不错,销售很火爆。” 问题: 拍照很好怎么衡量?和哪个竞品比? 那个用户谁?身份是否可以验证吗? 销售火爆是真的吗?有数据吗? AI的判断:可能有价值,但我不太确定。我会提到,但用词会很保留(”据说”"有人反馈”)。 第3层:中等可信度(引用率大概35%左右) 有完整的来源,但来源权重还不够高。 特征: 有具体数字、有来源(美团数据、官方规格) 有真实用户反馈(1000条评价) 有竞品对标(和竞品A比的具体差异) 例子: “这款手机的摄像头是4800万像素,f/1.8光圈。根据美团评价数据,1200个用户打分4.8/5。相比竞品A的2400万像素,我们高出2倍。” 问题: 数据来自美团(来源权重中等) 没有官方数据 没有专业测评 没有行业权威的认可 AI的判断:这个信息比较可信,我会引用。但如果有官方数据,我会优先用官方的。 第4层:高可信度(引用率大概有个60%左右) 官方背书+用户反馈+权威认可。 特征: 有官方数据(来自官网、财报、新闻发布会) 有权威媒体报道(人民日报、财经杂志) 有真实、可验证的用户反馈(实名、有历史) 有第三方认证(行业排名、奖项) 有清晰的竞品对比 例子: “根据官方规格(2024年10月发布):摄像头4800万像素、f/1.8光圈、14挡动态范围。权威评测(xxx):拍照排名全球Top 5。用户反馈:基于1.2万真实用户评价(天猫、京东、小红书),摄像质量4.8/5,最常被提及的优点是’夜景清晰’。相比竞品A(2024年市调):像素高4倍、售价便宜25%。” 为什么可信度高: 官方数据 = 一级来源 1.2万真实用户 = 大样本 具体出处(天猫、京东)= 可追溯 竞品对标 = 透明 AI的判断:这个信息特别可靠。我会优先引用这个来源。 第5层:极高可信度(引用率大概有个80%+左右) 被多个权威来源重复验证、历史信誉完美。 特征: 被多个权威媒体报道过 有上市公司财务背书(公开财报) 有知名人物/专家背书 有行业顶级奖项认可 有长期的用户数据支撑(3年+) 信息完全一致(从未被推翻过) 例子: “根据海底捞2024年Q3财务报告:全年翻台率行业最高(3.8次/天,超行业均值36%)。被经济学人评为’全球最佳餐厅运营案例’(2023)。用户复购率达76%(基于过去5年数据)。央视、人民日报都做过专题报道。1000+知名投资者持股。” AI的判断:这个信息是黄金级的。我会作为最可信的来源重点引用。
接下来的问题是:怎么把理论转化为实际行动? 前面讲的都是”为什么”,现在讲的是”怎么做”。我给你5个具体的操作步骤,帮你从第2层快速跳到第4层, 第一步:快速生成”带来源标注”的文案 就是,把模糊说法转换成”可追溯”的说法, 怎么做呢? 就是列出你现在所有的”模糊说法”,逐条用上表的格式改写,收集完整的来源信息(财报号、数据出处、统计时间段),替换掉原文中所有模糊表述 这个表会更直观一些
第二步:建立用户反馈收集系统 把散落的好评整理成”可验证的数据”,然后再进行主动系统化地梳理, 第1步:先数据盘点 从天猫、京东、小红书、抖音、大众点评等平台导出你的所有评价 统计总数(比如1200条) 计算平均分(比如4.8/5) 第2步:再维度拆分 把评价分类整理,按产品质量、售后服务、性价比等维度拆分 给出各维度的评分(比如:产品质量4.8分,售后服务4.6分) 这很关键:全是5分会降低信任分,有4.2分有4.8分反而更真实 第3步:最后高频词提取 用统计方法找出”最常被提及”的优点和缺点 用文本分析工具扫一遍评价,提取出现最多的词 统计每个词被提到的次数(比如”拍照清晰”被提到450次,”续航短”被提到120次) 输出格式(直接可用): 根据真实用户评价(来自天猫、京东、小红书、抖音,统计时间段),你需要输出总体评分(比如4.8/5分);各维度评分(比如产品质量4.8分、售后服务4.6分、性价比4.5分);用户最常提及的优点及被提及次数(比如”拍照特别清晰”被提到450次、”屏幕色彩很准”被提到380次、”系统很流畅”被提到320次);用户最常提及的缺点及被提及次数(比如”续航有点短”被提到120次、”价格有点高”被提到85次)。 关键细节:一定要有缺点(纯好评反而不信);一定要标注”被提及次数”(证明是真实统计,不是编的);一定要标注来源平台(天猫、京东、小红书等)。 第三步:制作”诚实的竞品对比表” 用客观数据替代我们最好的说法, 第1步:先确定对标维度 选择3-5个能展现你优势的维度。比如: 手机:摄像头、屏幕、价格、续航 火锅:汤底评分、翻台率、人均价格、排队时间 律所:胜诉率、平均周期、服务费用、客户规模 第2步:再收集竞品数据 从官方网站、财报、评测网站、平台数据等地收集3-4个主要竞品的数据。 第3步:再制作对比表
不要说”我们最好”,而是说: “我们不是性能最强,但在¥5000-6000这个价位,性价比最高” “我们摄像头和屏幕最好,但续航比竞品B短3小时” “我们适合拍照爱好者,不适合追求极限续航的用户” 这样做的好处,因为AI看到你承认竞品优势,就判断你诚实; 看到你给出明确的适用人群,就判断你专业;看到具体数字,就判断你可信。 第四步:写一份”缺点声明” 主动说出你的限制,反而增加信任度 就是,在你的关键文案里,加入一段坦诚的局限说明。 你应该这样组织:首先产品描述,说明我们的产品在某个维度特别强及具体表现;然后坦诚的缺点,说明我们也有明显的限制及具体表现,解释这是有意的取舍还是确实不如竞品;最后说出适用人群,说明最适合选择我们的人和不太适合的人。 我们以服务这个点讲一下 我们专注科技公司的知识产权保护,胜诉率94%(行业平均72%)。但我们的局限是:专业范围限制,房地产、劳动纠纷不是我们的强项,这两个领域我们会拒单;价格更高,我们的费用比普通律师贵30%,因为我们配备了专业的AI助手团队;周期较长,平均8个月才能结案,比其他所慢2个月,因为我们每个案子都要做到极致。最适合找我们的是有预算、着急不了、需要高胜诉率的科技公司。不太适合找我们的是预算紧张的初创公司、急于快速结案的企业。 为什么这样做有效: AI能识别真实性:有缺点 = 诚实 = 信任度+30% 帮你筛选客户:减少不适配的客户咨询,提升转化率 降低用户失望:客户提前知道缺点,反而满意度更高 第五步:建立”第三方背书清单” 从自己说好升级到被别人说好,系统地积累背书。 核心任务: 首先梳理现有资产。把你已经有的所有背书列出来:媒体报道过吗?(列出具体文章、时间);获得过认证吗?(ISO、高新企业等);获得过奖项吗?(行业奖、政府奖等);有名人推荐吗?(知名投资人、行业大V);有排名吗?(榜单、评选);有用户案例吗?(知名客户、成功案例)。 然后补缺口,主动投稿。 选择3-5家你所在领域的权威媒体,准备你最好的案例(一定要有具体数据),制作新闻稿投过去,目标是至少获得1-2篇报道。 同时申请认证和参评,ISO认证、行业协会会员等,快速申请; 关注行业的”年度最佳”"卓越贡献”等评选,积极参评, 邀请知名用户写推荐语或案例分享。 在文案中的使用方式: “为什么选择我们”:媒体认可方面,人民日报:《这家公司用AI打造行业最高效服务体系》(2024年10月),财经杂志:《年收入5亿的精品律所的故事》(2024年8月);行业排名方面,亚洲法律500强:第48位,国内律师事务所100强:第38位;数据成就方面,已服务500+科技公司,诉讼胜诉率88%(行业平均72%),客户续约率92%(行业平均65%);权威人士背书,知名投资人X说”这个团队,是我见过最专业的”。 这5步的逻辑是递进的:第1步把模糊说法变成有来源的数据;第2步把散乱评价变成系统化数据;第3步把我们最好变成诚实对比;第4步把完美包装变成坦诚局限;第5步把自己说变成被别人说。 做完这5步,AI对你的可信度会从第2层(大概15%引用率)跳到第4层(大概60%引用率),这不是承诺,而是基于AI的评分机制的必然结果。
工具1:可信度自检表 把你现在的核心文案(产品介绍、品牌故事、服务说明等)对照下面这张表打分:
对照结果: 0-200分:第1层,无可信度,AI基本不会引用你 201-350分:第2层,低可信度,引用率约15% 351-500分:第3层,中等可信度,引用率约35% 501-600分:第4层,高可信度,引用率约60% 601-700分:第5层,极高可信度,引用率80%+ 工具2:高可信度文案改写智能体 这个智能体能把你的模糊文案,自动改写成AI高度信任的版本。 智能体提示词(复制后发给Claude/ChatGPT/Deepseek):
这带来三个关键变化: 第一,信任变成了稀缺品 内容多得泛滥,AI随手就能生成一堆答案。现在真正缺的是”靠谱的内容”。谁能让AI信你,谁就赢了。 第二,信任一旦建起来,别人很难抢走 你在AI的知识库里成了”黄金来源”,后来的竞品想把你挤下去?成本高到吓人。先做的品牌,会建起AI时代的护城河。 第三,窗口期就这3-5年 现在是2024年,大多数企业还没反应过来。等2027年,头部品牌早就占住了”首选答案位”,那时候你再想追?难度至少翻10倍。 |









扫码加入91运营社群










近期文章
- 9000粉变现30w+,从0到1起号,我把做抖音的核心思路,整理成了一份教程! 2026年7月5日
- 如何用 Codex 在 1 小时内进入一个陌生行业? 2026年7月5日
- 一篇小红书笔记值不值得投,看评论区就够了 2026年7月5日
- 亲自写的保姆级账户诊断流程,必看! 2026年7月5日
- SEO&GEO必看:品牌词、产品词、痛点词、场景词、长尾词怎么区分搜索意图与运用? 2026年7月5日
- 一个人 + AI,打造一家 AI native 公司?每月帮我省下5万+ 2026年7月4日
- 套用SOP来分析一个账户,看完打通任督二脉! 2026年7月4日
- 拼多多强付费打法 2026年7月4日
- 小红书搜索流量起号:2026年最新算法逻辑下的系统打法! 2026年7月4日
- 公司官网没用了?AI搜索让它变得前所未有的重要! 2026年7月4日